

I’d like to be able to have a region that is densely packed with non-overlapping circles, whose sizes vary spatially in a pre-defined way. There are lots of resources for Poisson-disk sampling, but that doesn’t result in snugly packed circles. Time to do some tinkering!
Random search
The laziest way to do this: try to add a circle at a random point, and see if it fits. Repeat until you fail for way too long. This will give non-overlapping circles, but they are not densely packed.

This found 264 valid circles. I had the algorithm try 50,000 times, and it only added 7 circles during its second half. Super inefficient at the end!
One of the main problems here is that it doesn’t know which regions are covered, so it picks useless points way too often, and increasingly so at the end.
Pruning
Let’s start with a set of candidate locations instead, rather than a continuous space. Then whenever we add a circle, we can remove the too-close points from the list of candidates, and continue.
First, we remove all the candidates that are too close to a wall. Then the first candidate will be a valid circle, so we add that. Then we check the distance to all the other candidates, and remove the ones that are too close to be valid. And repeat!
The order of the candidates becomes important, then. For example, if they are randomly ordered, this will quickly reduce the number of candidates, but will not be densely packed. Here, the circles are in black, and the candidate positions are in blue.

This was much faster than the entirely random search, but still gave loosely packed circles. Instead, we can sort by their location, say their y-position:

Which increases the number of circles by 20%! Excellent.
Now how expensive is this approach? Let’s say there are n_p candidate points, r is the uniform radius, and the dimensions are width and height w,h. The number of points should be proportional to the area of the region, n_p=\alpha w h. The resulting number of circles is approximately n_c \approx \frac{wh}{\pi r^2}.
If we weren’t discarding the bad points, we would have to check every point at each iteration. That means that the number of computations would be N=\sum_{i=1}^{n_c} n_p = h^2 w^2 \alpha/(\pi r^2).
If we are discarding points, they’ll be discarded at a roughly uniform rate. So at iteration i, we should have n_p(1-i/n_c) points remaining. Then N=\sum_{i=1}^{n_c}n_p (1-i/n_c) = n_p(n_c-1)/2 =\frac{h^2w^2 \alpha}{2 \pi r^2}-\frac{h w \alpha}{2}, which means that we’ve halved the necessary computations by pruning.
A further optimization would be to only check points that are within a distance of twice the maximum radius. Since the points are sorted by their y-position, this works well. In this example case, this means that a swath of approximately \beta n_p 2 r/h points are checked in each iteration. By experimentation, \beta\approx 0.6. This reduces the number of computations to N=\sum_{i=1}^{n_c} (\beta n_p 2 r/h) = \frac{h w^2 \alpha \beta}{\pi r}. Removing that factor of h from the expense is very helpful!
On a similar note, if you could also limit the x-width of each check, that would be even better. Then we could have N=n_c (\gamma n_p (2r)^2/(wh)) = \frac{4 h w \alpha \gamma}{\pi}, with \gamma\approx 0.4, which is much, much faster. That’s now linear with the area of the region!
Unfortunately, our 1D list of points isn’t great for checking squares. So let’s use a 2D array instead! This gives the points a useful property: it’s easy to know how far they are from any other point, just based on their storage structure. Now we can easily achieve that area-proportional method!
Unfortunately, this will result in circles that are on a grid, and the circles won’t be touching perfectly. That can be fixed with a little shift based on gradients. If you know the gradient of the distance functions and local radii, you can shift the circle down until it’s touching, and life will be OK again.
Halftoning
Of course, I have to use this for halftoning with dots and circles. Time for some quick math. Define the min and max radii of the circles to be r_{min},r_{max}, and a packing efficiency of \phi. The radius of a given dot is r. The image intensity (compared to darkness) is I_0=1-k_0.
First, dots. Let’s say that the radius of the drawn dot is r_{dot}. The average darkness of a region is k=\phi \pi r_{dot}^2/(\pi r^2). If scale the input to be between the minimum and maximum achievable values with these radii, and solve for r, we get
r=r_{max}/\sqrt{ 1+k_0 \left( \left(\frac{r_{max}}{r_{min}}\right)^2-1 \right) }.
If we do the same sort of thing for an outlined circle, we have k=\phi 2\pi r w/(\pi r^2), where w is the width of the line. Then the output radius is
r=r_{max}/\left( 1+k_0 \left(\frac{r_{max}}{r_{min}}-1 \right) \right).
Results

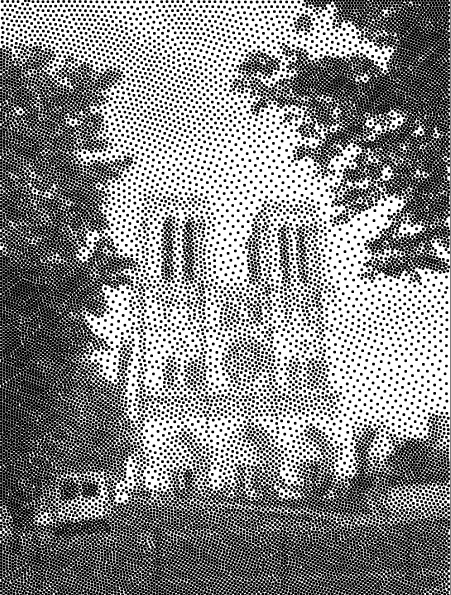


It works!
I’ve made these images with a Processing-based sketch, which I will describe and release in another post!
7 replies on “Approximate Circle Packing”
Very good explain, I am now studying the circle pack, but I am not capable to produce pictures as beautiful as what you do.
Thanks! If you make something cool, please let me know.
Hey Esteban,
Is this program open source? Or would you consider a custom modification of it?
Desired upgrades…
Id like to specify pre determines circle sizes that the program can use including varied wall weights.
Add a minimum space between each circle.
(im going to use the program to design a cut path into which Ill insert glass tubing – illuminated from behind). Id love to share more about the project in case you have insight or are open to collaborating…
It is open source, you can get its code here: https://github.com/ehufsted/HalftonePAL
So you’re thinking of having a discrete number of circle sizes, with different wall widths? That shouldn’t be too hard to implement.
That sounds like a cool project, shoot me an email about it! My address is on my CV (to keep bots from scraping it).
Hey man you’re work is incredible, you’re super talented! Is there any way you can make this work with pre determined circle sizes?
Keep up the awesome work!
I discovered halftonepal. Awesome job. One update I suggest is to tell the user to wait in case of processing taking too long. My 8gb 2012 Mac book pro takes time. I hate to go back to windows. Is there a non processing version?
Glad you like it! It does take a while sometimes, you’re right.
I’m hoping to make a C# version sometime in the future, once I have a bit more free time. But that won’t be for months, at least.